
How is MLOps Different from DevOps?
- by 7wData
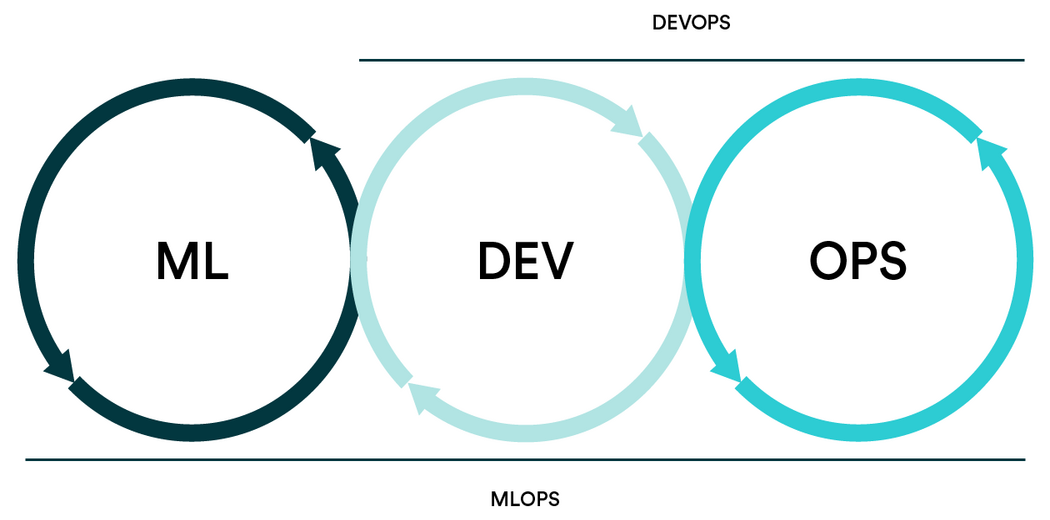
DevOps practices include continuous integration and deployment, which are CI/CD. MLOps talks about CI/CD and ongoing training, which is why DevOps practices aren’t enough to produce Machine Learning applications. In this article, I explained the important features of MLOps and the key differences from traditional DevOps practices.
DevOps – Development and Operations
Today’s competitive world is about how quickly you make your features available to the end user. DevOps helps the project team quickly integrate new features and make them available to end users using an automated
DevOps pipeline.
DevOps uses two key components throughout its lifecycle:
1. Continuous Integration: Merging the code base into a central code repository such as git and bitbucket, automating the software system build process with Jenkins, and running automated test cases.
2. Continuous Delivery: Once new features are developed, tested, and integrated into the continuous integration phase, they must be automatically deployed to make them available to end users. This automated build and deployment are done in the developer’s continuous delivery phase.
When a project is deployed, and users start using it, it’s important to track various metrics. Under DevOps monitoring, an engineer takes care of several things like application monitoring, usage monitoring, visualization of key metrics, etc.
Machine Learning Vs. Traditional Software Development
According to the paper “Hidden Technical Debt in Machine Learning Systems,” Only a fraction of a real ML system consists of ML code. Along with the ML code, we need to consider data cleaning, data versioning, model versioning, and continuous training of models on a new data set. Machine learning system testing is different from the traditional software testing mechanism. Testing a Machine Learning application is more than just unit testing. We must consider data checks and data drift, model drift, and performance evaluation of the model deployed to production.
• Machine learning systems are highly experimental. You can’t guarantee that an algorithm will work in advance without doing some experiments first. Therefore, there is a need to track various experiments, feature engineering steps, model parameters, metrics, etc., to know which experimental algorithm the optimal results are achieved in the future.
• The deployment of machine learning models is particular, depending on the problem they are trying to solve. Most parts of the machine learning process involve things related to data. And therefore, the machine learning pipeline has several steps, including data processing, feature engineering, model training, model registry, and model deployment.
• Model output should be consistent over time. Therefore, we need to track data distribution and other statistical measurements related to data over a period. The live data should be similar to the data used to train the model.
• People who develop machine learning models do not focus on software practices because they often do not come from a software background.
MLOps – Operations in Machine Learning
MLOps or ML Ops is a set of practices that aim to reliably and efficiently deploy and maintain machine learning models in production. The word is a portmanteau of “machine learning” and the continuous development of DevOps in software.
MLS is a combination of DevOps, machine learning, and data engineering. Building on the existing DevOps approach, MLOps solutions are developed to increase reusability, facilitate automation, data shift management, model versioning, experiment tracking, ongoing training, and obtain richer and more consistent insights in a machine learning project.
Andrew Ng recently talked about how the machine learning community can use MLOps to build high-quality datasets and AI systems that are repeatable and systematic.
[Social9_Share class=”s9-widget-wrapper”]
Upcoming Events
From Text to Value: Pairing Text Analytics and Generative AI
21 May 2024
5 PM CET – 6 PM CET
Read More