
Data Science Automation For Big Data and IoT Environments
- by 7wData
data science sits at the core of any analytical exercise conducted on a big data or Internet of Things (IoT) environment. data science involves a wide array of technologies, business, and machine-learning algorithms. The purpose of data science is not only to do machine learning or statistical analysis, but also to derive insights out of the data that a user with no statistics knowledge can understand.
In a fast-paced environment such as big data and IoT, where the type of data might vary over the course of time, it becomes difficult to maintain and re-create the models each and every time. This gap calls for an automated way to manage the data-science algorithms in those environments. The rise of data science was intended to move us away from a rules-based system to a system in which a machine learns rules for its automation by itself. Machine learning makes data science inherently partially automated. The half of data science that requires manual intervention is still to be automated. However, those are areas that involve the experience and wisdom of a people: a data scientist, a business expert, a software developer, a data integrator, everyone who currently contributes to making a data-science project operational. This makes it difficult to automate every aspect of data science. However, we can think of data science automation as a two level architecture, wherein:
– All the individual automated components are interconnected to form a coherent data-science system
We can think of a data-science system as automated when it’s capable enough to solve our problem whenever we throw a data set at it. Also, it should be intelligent enough to provide us with all possible solutions in a language that we can understand.
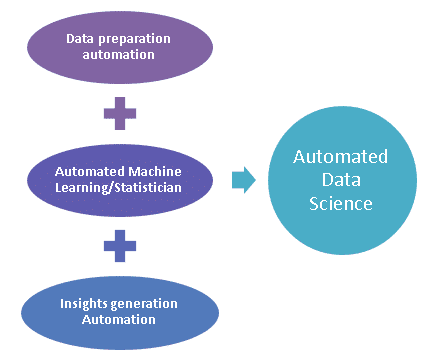
Data preparation, machine learning, domain knowledge, and result interpretation are four major tasks required to execute a data-science project successfully. All these tasks have to be converted to automated modules to create an automated data-science system (Figure 1).
Data preparation is a repetitive task that has to be done every time when creating models. Data extraction, data cleaning, and data transformations such as imputing null values and algorithm-specific transformations are some tasks that fall into this category. Many organizations automate these tasks and have branded the engine as a data science automation tool. However, most of these tools use rule-based logic for automating data-preprocessing tasks. Is this the right approach? Do we need rule-based systems to automate data science, which was born to end rule-based systems? Well, No. We need data preprocessing automated by machine learning itself. For example, the decision regarding what preprocessing function has to be applied on the data for a problem is to be made by machines themselves.
Feature engineering is another area of data preparation that requires automation. Feature engineering is a technique to convert raw data into attributes/predictors that improve the accuracy of a machine-learning project. Feature-engineering automation is still at a nascent stage and an active area of research. Data scientists from MIT are making incredible progress toward developing a “deep feature synthesis” algorithm capable of generating features from raw data.
This is an area of data-science automation where statistical routines are automated. The system executes the best algorithm based on the provided data set. It hides the intricacies and mathematical complexity of algorithms from the user, making it available to the masses. The user needs to provide the automated statistician with data.
[Social9_Share class=”s9-widget-wrapper”]
Upcoming Events
From Text to Value: Pairing Text Analytics and Generative AI
21 May 2024
5 PM CET – 6 PM CET
Read MoreYou Might Be Interested In
3 Ways to Use Big Data to Drive Your Content Marketing Strategy
15 May, 2016Now I’m preaching to the choir when I tell you that big data is the future. You all know that …
Your Brain Reveals Who Your Friends Are
1 Feb, 2018Summary: By looking at how the brain responds to video clips, researchers are able to determine who your friends may …
7 Things to Look before Picking Your Data Discovery Vendor
7 Apr, 2017Data Discovery Tools: also called Data Visualization Tool, sometimes also referred to as Data Analytics tools. These tools are talk …
Recent Jobs
Do You Want to Share Your Story?
Bring your insights on Data, Visualization, Innovation or Business Agility to our community. Let them learn from your experience.
Privacy Overview
Get the 3 STEPS
To Drive Analytics Adoption
And manage change
