
Building the Machine Learning Infrastructure
- by 7wData
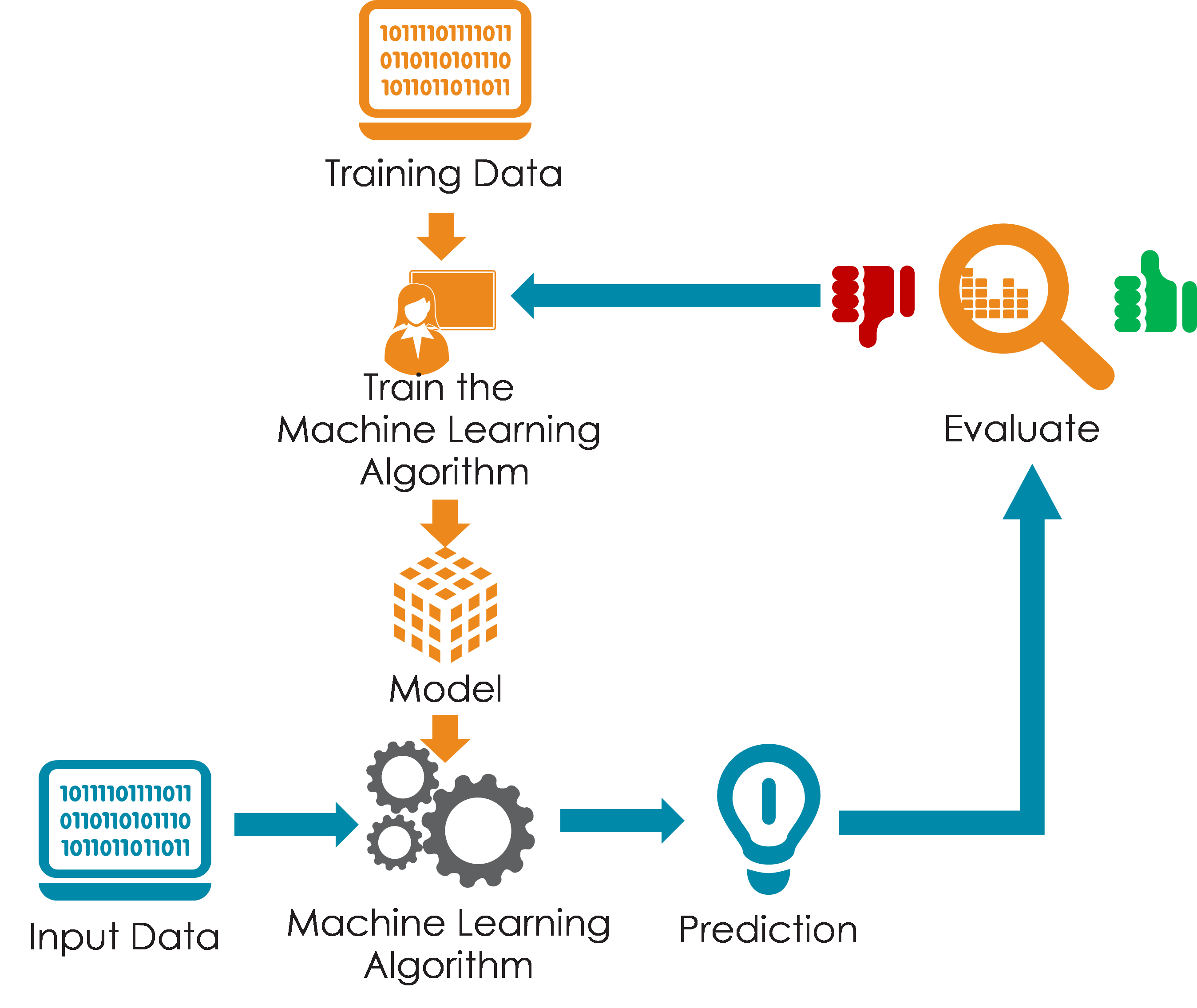
Making intelligent and accurate predictions is the core objective of Machine Learning and artificial intelligence applications. To achieve that objective, the Machine Learning or artificial intelligence application needs clean and well-organized information in a robust ecosystem architecture. Machine Learning (ML) is the process of a computer system making a prediction based on samples of past observations. There are various types of ML methods. One of the approaches is where the ML algorithm is trained using a labeled or unlabeled training data set to produce a model. New input data is introduced to the ML algorithm and it makes a prediction based on the model. The prediction is evaluated for accuracy and if the accuracy is acceptable, the ML algorithm is deployed. If the accuracy is not acceptable, the ML algorithm is trained again with an augmented training data set. This is just a very high-level example as there are many factors and other steps involved. Artificial intelligence (AI) takes machine learning to a more dynamic level producing a feedback loop in which an algorithm can learn from its experiences. In many cases an intelligent agent is used to perceive an environment and detect changes in the environment and then reacts to that change based on information and rules it has been taught. Every AI program is dependent on information to make predictions and decisions. That information needs to be structured in the appropriate context to make informed decisions. An example of appropriate context comes from an example application of a robotic vacuum cleaner [1] that would navigate a room on its own and how it was measured that it was doing a “good job”. The metric chosen was focused on “picking up the dirt” and therefore to measure the volume of dirt it vacuumed and the amount of time it spent collecting it. Based on this objective the vacuum would learn that when it bumped into an object dirt would get picked up, and thus it learned to identify where the most dirt was collected next to furniture or some other object and would bump the object harder to dislodge any additional dirt, such as knocking over a plant and dumping the dirt on the floor and then collecting it. It consumed more energy which in turn cost more, not to mention causing a mess, but it did a “good job” based on the metric by which it was measured. It based this on the context of the information to which it had access. Keeping this type of approach continued to increase expenses and decrease benefits. The solution was to change the perspective to a new metric of “clean the room and keep it clean” and thus the application learned to just focus on expending energy only in the areas that needed to be vacuumed and reduced the cost of energy consumed by the device. It needed additional sensors to accomplish this new mission which at first sight would seem to increase cost, but the reduction of energy used was paid back with each occurrence producing significant value. It functioned on the terms of efficiency. For AI, machine learning, and any type of analytics, the better the information is modeled, structured and organized for fast retrieval, the more effective and efficient the processing will perform. Conversely the more complex the model or structure, the more complex the processing. AI and ML algorithms that search for patterns in unstructured or non-relational data still need structure. Even schema-less data must be wrangled into meaningful structures.
[Social9_Share class=”s9-widget-wrapper”]
Upcoming Events
From Text to Value: Pairing Text Analytics and Generative AI
21 May 2024
5 PM CET – 6 PM CET
Read More