
Optimizing Project Staffing to Improve Profitability with Cortana Intelligence
- by 7wData
This post is by Francesca Lazzeri and Hong Lu, Data Scientists, and Ilan Reiter, Principal Data Science Manager, at Microsoft.
Recent advancements in machine learning and big data technologies are allowing companies to apply better staffing strategies by taking advantage of historical data. Ensuring that the right people get assigned to the right projects is critical not only for the success of a given project but also for the overall profitability of an organization. At most companies, project staffing is typically done manually by project managers, based on staff availability and prior knowledge of individuals’ past performance. This process is not only time-consuming but the results can often be sub-optimal. The same process can be done much more effectively by taking advantage of historical data and advanced ML techniques.
We recently developed a recommendations-based staff allocation solution for Baker Tilly Virchow Krause, LLP, a professional services company. Baker Tilly is a full-service accounting and advisory firm with a focus on industry and services specialization. The solution we have built recommends optimal staff composition as well as individual staff with the right experience and expertise for Baker Tilly’s new projects. By aligning staff experience with project needs, we help project managers at Baker Tilly perform better and faster staff allocation.
The end goal of our solution is to improve profitability at Baker Tilly. Based on our offline evaluation, we expect a 4-5% improvement on profits for the projects that employ our solution. The final solution has been integrated with Baker Tilly’s internal practice management system and will be evaluated in a few pilot teams before being implemented across all teams.
The solution developed is divided into the following two parts and the outputs of the two parts are combined to generate the final staff recommendations:
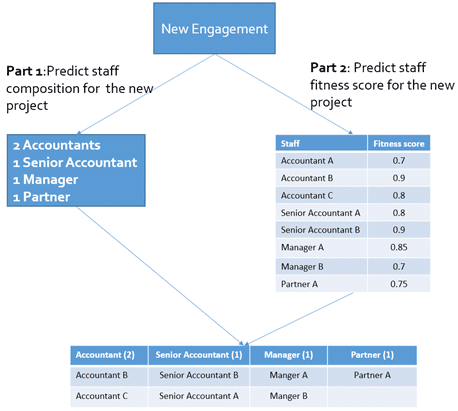
Part 1: Predict staff composition, e.g. one senior accountant and two accounting assistants, for a new project. In this part, we use K-Nearest Neighborhood (KNN) to perform prediction based on historical projects with similar properties like project type and industry.
Part 2: Compute Staff Fitness Score (Rating) for a new project. For this second part, we applied a content-based recommendation algorithm developed in R and executed by Execute R Script modules in Azure ML.
The figure below summarizes the workflow design of this Proof of Concept (PoC):
Baker Tilly has integrated the solution within their practice management tools – new projects in Baker Tilly’s database are processed daily by the Azure ML web service and results are consumed by project managers in Baker Tilly’s practice management system. The workforce placement recommendation results are also visualized on a real-time PowerBI dashboard that can be used by data analysts and executives at Baker Tilly to monitor project allocation and performance over time.
The figure below shows the solution architecture in detail:
In this step, we used KNN to predict staff composition (i.e. numbers of each staff classification/title) on a new project, using historical project data. We split the dataset in the following way:
We found historical projects similar to new projects based on project properties such as Project Type, Total Billing, Industry, Client, Revenue Range, etc. We assigned different weights to each project property based on business rules and standards. We also removed any data that had negative contribution margin (profit). For each staff classification, staff count is predicted by computing a weighted sum of similar historical projects’ staff counts of the corresponding staff classification. Using Accountant as an example:
The weight of each historical project is:
The final weights are normalized so that the sum of all weights are 1. Before calculating the weighted sum, we removed 10% outliers with high values and 10% outliers with low values.
[Social9_Share class=”s9-widget-wrapper”]
Upcoming Events
From Text to Value: Pairing Text Analytics and Generative AI
21 May 2024
5 PM CET – 6 PM CET
Read More