
The Hybrid Cloud for High Availability
- by 7wData
The private cloud remains the best choice for many applications for a variety of reasons, while the public cloud has become a more cost-effective choice for others. This split has resulted — intentionally or not — in the vast majority of organizations now having a hybrid cloud. But there are many different ways to leverage the versatility and agility afforded in a hybrid cloud environment, especially when it comes to the different high availability and disaster recovery protections needed for different applications.
This article examines the hybrid cloud from the perspective of high availability (HA) and disaster recovery (DR), and provides some practical suggestions for avoiding potential pitfalls.
The carrier-class infrastructure implemented by cloud service providers (CSPs) gives the public cloud a resiliency that is far superior to what could be justified for a single enterprise. Redundancies within every data center, with multiple data centers in every region and multiple regions around the globe give the cloud unprecedented versatility, scalability and reliability. But failures can and do occur, and some of these failures cause downtime at the application level for customers who have not made special provisions to assure high availability.
While all CSPs define “downtime” somewhat differently, all exclude certain causes of downtime at the application level. In effect, the service level agreements (SLAs) only guarantee the equivalent of “dial tone” for the physical server or virtual machine (VM), or specifically, that at least one instance will have connectivity to the external network if two or more instances are deployed across different availability zones.
Here are just a few examples of some common causes of downtime excluded from SLAs:
It is reasonable, of course, for CSPs to exclude these and other causes of downtime that are beyond their control. It would be irresponsible, however, for IT professionals to use these exclusions as excuses for not providing adequate HA and/or DR protections for critical applications.
Properly leveraging the cloud’s resilient infrastructure requires understanding some important differences between “failures” and “disasters” because these differences have a direct impact on HA and DR configurations. Failures are short in duration and small in scale, affecting a single server or rack, or the power or cooling in a single datacenter. Disasters have more enduring and more widespread impacts, potentially affecting multiple data centers in ways that preclude rapid recovery.
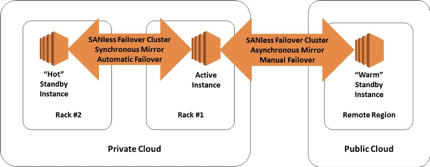
The most consequential effect involves the location of the redundant resources (systems, software and data), which can be local — on a Local Area Network — for recovering from a localized failure. By contrast, the redundant resources required to recover from a widespread disaster must span a Wide Area Network.
For database applications that require high transactional throughput performance, the ability to replicate the active instance’s data synchronously across the LAN enables the standby instance to be “hot” and ready to take over immediately in the event of a failure. Such rapid, automatic recovery should be the goal of all HA provisions.
Data is normally replicated asynchronously in DR configurations to prevent the WAN’s latency from adversely impacting on the throughput performance in the active instance. This means that updates being made to the standby instance always get made after those being made to the active instance, making the standby “warm” and resulting in an unavoidable delay when using a manual recovery process.
All three major CSPs accommodate these differences with redundancies both within and across data centers. Of particular interest is the variously named “availability zone” that makes it possible to combine the synchronous replication available on a LAN with the geographical separation afforded by the WAN.
[Social9_Share class=”s9-widget-wrapper”]
Upcoming Events
From Text to Value: Pairing Text Analytics and Generative AI
21 May 2024
5 PM CET – 6 PM CET
Read More