
Data Catalogs Are Dead; Long Live Data Discovery
- by 7wData
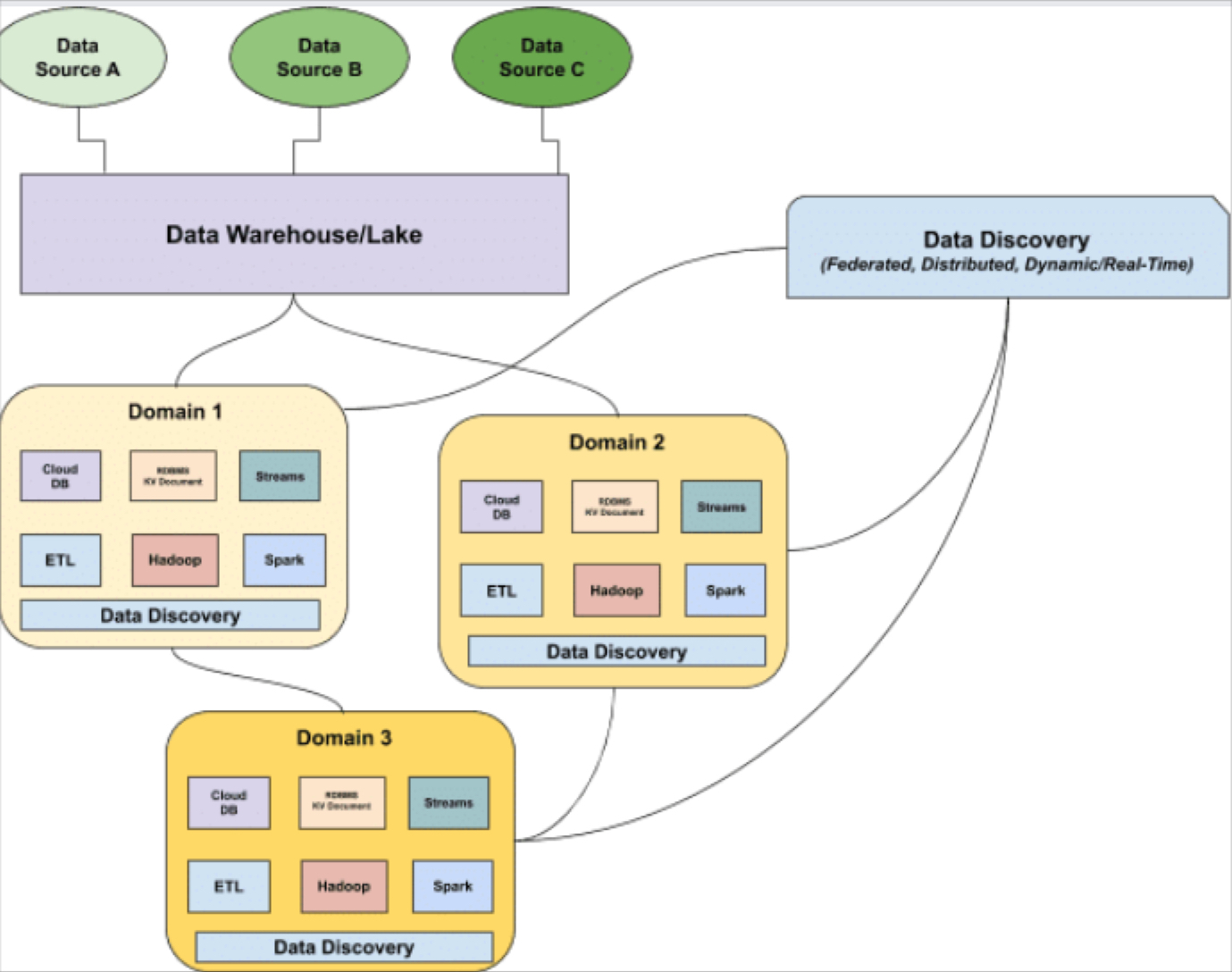
It’s no secret: knowing where your data lives and who has access to it is fundamental to understanding its impact on your business. In fact, when it comes to building a successful data platform, it’s critical that your data is both organized and centralized, while also easily discoverable.
Analogous to a physical library catalog, data catalogs serve as an inventory of metadata and give users the information necessary to evaluate data accessibility, health, and location. In our age of self-service business intelligence, data catalogs have also emerged as a powerful tool for data management and data governance.
Not surprisingly, for most data leaders, one of their first imperatives is to build a data catalog.
At the bare minimum, a data catalog should answer:
Still, as data operations mature and data pipelines become increasingly complex, traditional data catalogs often fall short of meeting these requirements.
Here’s why some of the best data engineering teams are innovating their approach to metadata management – and what they’re doing instead:
While data catalogs have the ability to document data, the fundamental challenge of allowing users to “discover” and glean meaningful, real-time insights about the health of your data has largely remained unsolved.
Data catalogs as we know them are unable to keep pace with this new reality for three primary reasons: (1) lack of automation, (2) inability to scale with the growth and diversity of your data stack, and (3) their undistributed format.
Traditional data catalogs and governance methodologies typically rely on data teams to do the heavy lifting of manual data entry, holding them responsible for updating the catalog as data assets evolve. This approach is not only time-intensive, but requires significant manual toil that could otherwise be automated, freeing time up for data engineers and analysts to focus on projects that actually move the needle.
As a data professional, understanding the state of your data is a constant battle and speaks to the need for greater, more customized automation. Perhaps this scenario rings a bell:
Before stakeholder meetings, do you often find yourself frantically pinging Slack channels to figure out what data sets feed a specific report or model you are using – and why on earth the data stopped arriving last week? To cope with this, do you and your team huddle together in a room and start whiteboarding all of the various connections upstream and downstream for a specific key report?
I’ll spare you the gory details, but it probably looked something like this:
If this hits home, you’re not alone. Many companies that need to solve this dependency jigsaw puzzle embark on a multi-year process to manually map out all their data assets. Some are able to dedicate resources to build short-term hacks or even in-house tools that allow them to search and explore their data. Even if it gets you to the end goal, this poses a heavy burden on the data organization, costing your data engineering team time and money that could have been spent on other things, like product development or actually using the data.
[Social9_Share class=”s9-widget-wrapper”]
Upcoming Events
From Text to Value: Pairing Text Analytics and Generative AI
21 May 2024
5 PM CET – 6 PM CET
Read More