
Data Pipelines of Tomorrow
- by 7wData
By the time humans got around to creating systems that imported user data at regular fixed intervals (e.g., banks with nightly upload over ETL), they also began to see the potential for input data to provide an effective feedback loop on the system itself. Data was, by then after all, not just a message, but a key part of how the data pipeline — or the organization using it — would construct and harmonize itself.
In business systems, analytics data was also used to improve the process or product in question. Banking data, for instance, was fed back to the consumer as account balance statements, while also being used to optimize the business process. The data was used to automatically calculate incentive interest rates and fees for account holders, for example, and determine for product owners which demographic preferred which financial products.
Nowadays, data (and data pipelines) are pretty ubiquitous: data no longer flows merely from nightly batch ingestion to central data stores and out to user dashboards, but typically in both directions. Consumer devices may even have their own data pipelines built in, which provide input and feedback to the larger system. This polydirectionality of data flowing through such systems is just one of many factors causing the amount of data in the greater datasphere to grow exponentially.
Indeed, as IDC points out, the 16.1 zettabytes of user data generated around the world in 2016 is expected to grow tenfold to 163 zettabytes by 2025. Far from the days of nightly import cycles at the bank, users in this world will be interacting with a data-driven endpoint on average once every 18 seconds.
To get a better sense of this future, we'll look at data — and data pipelines — from a few different perspectives: which direction the data of the future will flow, what data engineers can expect with distributed ledgers and blockchain technologies, and how regulatory compliance will work in a future with the immutable, ordered event log. We'll also consider pipeline requirements like those of scalability, performance, and design(ability) for our future pipelines.
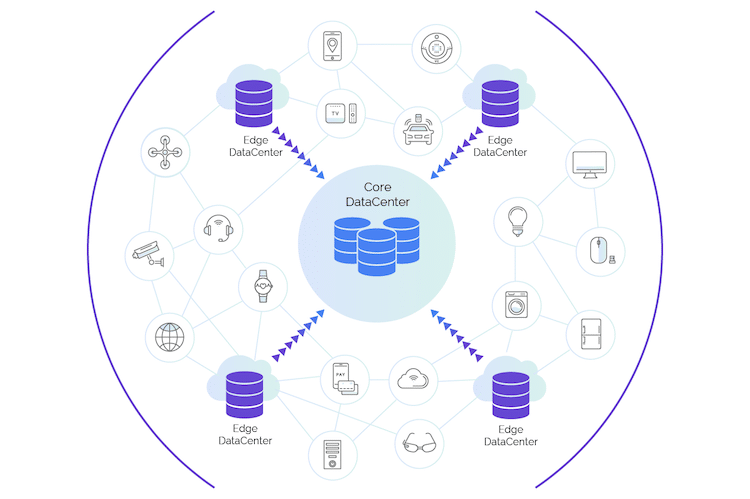
Today, data often runs in near real time, polydirectionally, is fairly ubiquitous to users, and can even help save lives. Consider the core-to-endpoint (also known as core-to-edge, or C2E) data pipeline.
In the past, a data pipeline was something where data went in one end (often as a batch import) and came out the other end, in the form of analytics or a dashboard that helped (an often fairly limited group of) users understand the data.
In a C2E model, data may run polydirectionally, that is, from many points of ingestion back to central or edge data stores for processing, aggregation or analytics, and then back out to endpoint devices or dashboards for more processing. The data can also serve as instructions or training data for subsequent systems that run on AI (more on this later). There's no one-size-fits-all for data pipelines, anymore.
Where can we see examples of C2E pipelines?
Order is critical for transactions on the blockchain. You could expect that, if events were written in an arbitrary order, it would be impossible to reconstruct the state of your data at any point in time, or who did what to whom and when in a given transaction.
However, whenever data is partitioned and distributed across a network, one must consider the CAP Theorem, that is, the idea that a user of such a network may, at scale, need to tweak the tradeoff between data consistency and availability. For this reason, we expect to see more users implementing their distributed ledgers as tunably-consistent distributed databases.
Currently, a pub-sub architecture is what moves data from one datastore or location to another.
[Social9_Share class=”s9-widget-wrapper”]
Upcoming Events
From Text to Value: Pairing Text Analytics and Generative AI
21 May 2024
5 PM CET – 6 PM CET
Read More