

For data teams, broken data pipelines, stale dashboards, and 5 a.m. fire drills are par for the course, particularly as data workflows ingest more and more data from disparate sources. Drawing inspiration from software development, we call this phenomenon data downtime— but how can we proactively prevent bad data from striking in the first place?
In this article, I share three key strategies some of the best data organizations in the industry are leveraging to restore trust in their data.
Recently, a customer posed this question: “How do you prevent data downtime?”
As a data leader for a global logistics company, his team was responsible for serving terabytes of data to hundreds of stakeholders per day. Given the scale and speed at which they were moving, data downtime, in other words, periods of time when data is fully or partially missing, erroneous, or otherwise inaccurate, was an all-too-common occurrence.
Time and again, someone in Marketing (or Operations or Sales or any other business function that uses data) noticed the metrics in their Tableau dashboard looked off, reached out to alert him, and then his team stopped whatever they were doing to troubleshoot the issue. In the process, his stakeholder lost trust in the data, and valuable time and resources were diverted from actually building to firefight this incident.
Perhaps you can relate?
The rise of data downtime
The idea of preventing downtime is standard practice across many industries that rely on functioning systems to run their business, from preventative maintenance in manufacturing to error monitoring in software engineering (queue the dreaded 404 page…).
Yet, many of the same companies that tout their data-driven credentials aren’t investing in preventing broken pipelines or identifying poor-quality data before it moves downstream. Instead of being proactive about data downtime, they’re reactive, playing whack-a-mole with bad data instead of focusing on preventing it in the first place.
Fortunately, there’s hope. Some of the most forward-thinking data teams have developed best practices for preventing data downtime and stopping broken pipelines and inaccurate dashboards in their tracks, before your CEO has a chance to ask the dreaded question: “what happened here?!”
Below, I share 3 key steps you can take to preventing bad data from corrupting your otherwise good pipelines:
Test your data. And test your data some more.

In 2021, data testing is table stakes.
In the same way that software engineers unit test their code, data teams should validate their data across every stage of the pipeline through end-to-end testing. At its core, testing helps you measure whether your data and code are performing as you assume it should.
Schema tests and custom-fixed data tests are both common methods, and can help confirm your data pipelines are working correctly in expected scenarios. These tests look for warning signs like null values and referential integrity, and allows you to set manual thresholds and identify outliers that may indicate a problem. When applied programmatically across every stage of your pipeline, data testing can help you detect and identify issues before they become data disasters.
Understand data lineage and downstream impacts
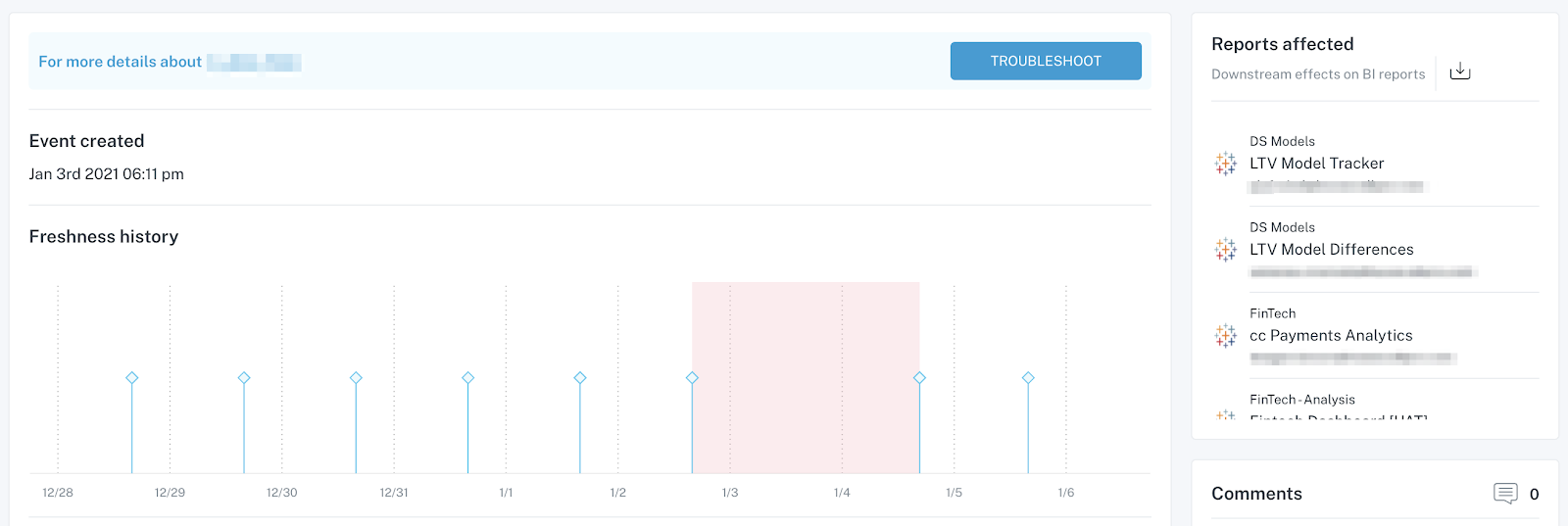
Often, data downtime is the unintended consequence of an innocent change, far upstream from an end consumer relying on a data asset that no member of the data team was even aware of. This is a direct result of poor data lineage — I’ve called it the “You’re Using THAT Table?!”problem.
Data lineage, simply put, is the end-to-end mapping of upstream and downstream dependencies of your data, from ingestion to analytics. Data lineage empowers data teams to understand every dependency, including which reports and dashboards rely on which data sources, and what specific transformations and modeling take place at every stage.
When data lineage is incorporated into your platform, especially at the field and table level, all potential impacts of any changes can be forecasted and communicated to users at every stage of the data lifecycle to offset any unexpected impacts.
While downstream lineage and its associated business use cases are important, don’t neglect understanding which data scientists or engineers are accessing data at the warehouse and lake levels, too. Pushing a change without their knowledge could disrupt time-intensive modeling projects or infrastructure development.
Make metadata a priority, and treat it like one
Lineage and metadata go hand-in-hand when it comes preventing data downtime. Tagging data as part of your lineage practice allows you to specify how the data is being used and by whom, reducing the likelihood of misapplied or broken data.
Until all too recently, however, metadata was treated like those empty Amazon boxes you SWEAR you’re going to use one day — hoarded and soon forgotten.
As companies invest in more specialized data tools, more and more organizations are realizing that metadata serves as a seamless connection point throughout your increasingly complex tech stack, ensuring your data is reliable and up-to-date across every solution and stage of the pipeline. Metadata is specifically crucial to not just understanding which consumers are affected by data downtime, but also informing how data assets are connected so data engineers can more collaboratively and quickly resolve incidents should they occur.
When metadata is applied according to business applications, you unlock a powerful understanding of how your data drives insights and decision making for the rest of your company.
The future of data downtime

So, where does this leave us when it comes to realizing our dream of a world without data downtime?
Well, like death and taxes, data errors are unavoidable. But when metadata is prioritized, lineage is understood, and both are mapped to testing and observability, the negative impacts on your business — the true cost of data downtime — is largely preventable.
I’m predicting that the future of data downtime is dark. And that’s a good thing. The more we can prevent data downtime from causing headaches and fire drills, the more our data teams can focus on projects that drive results and move the business forward with trusted, reliable, and powerful data.
Have some data downtime stories to share? I’m all ears. Reach out to Barr Moses.
